
After my last post, Michael contacted me and explained
that I could simplify the import. The apoc.load.json()apoc.create.relationship()
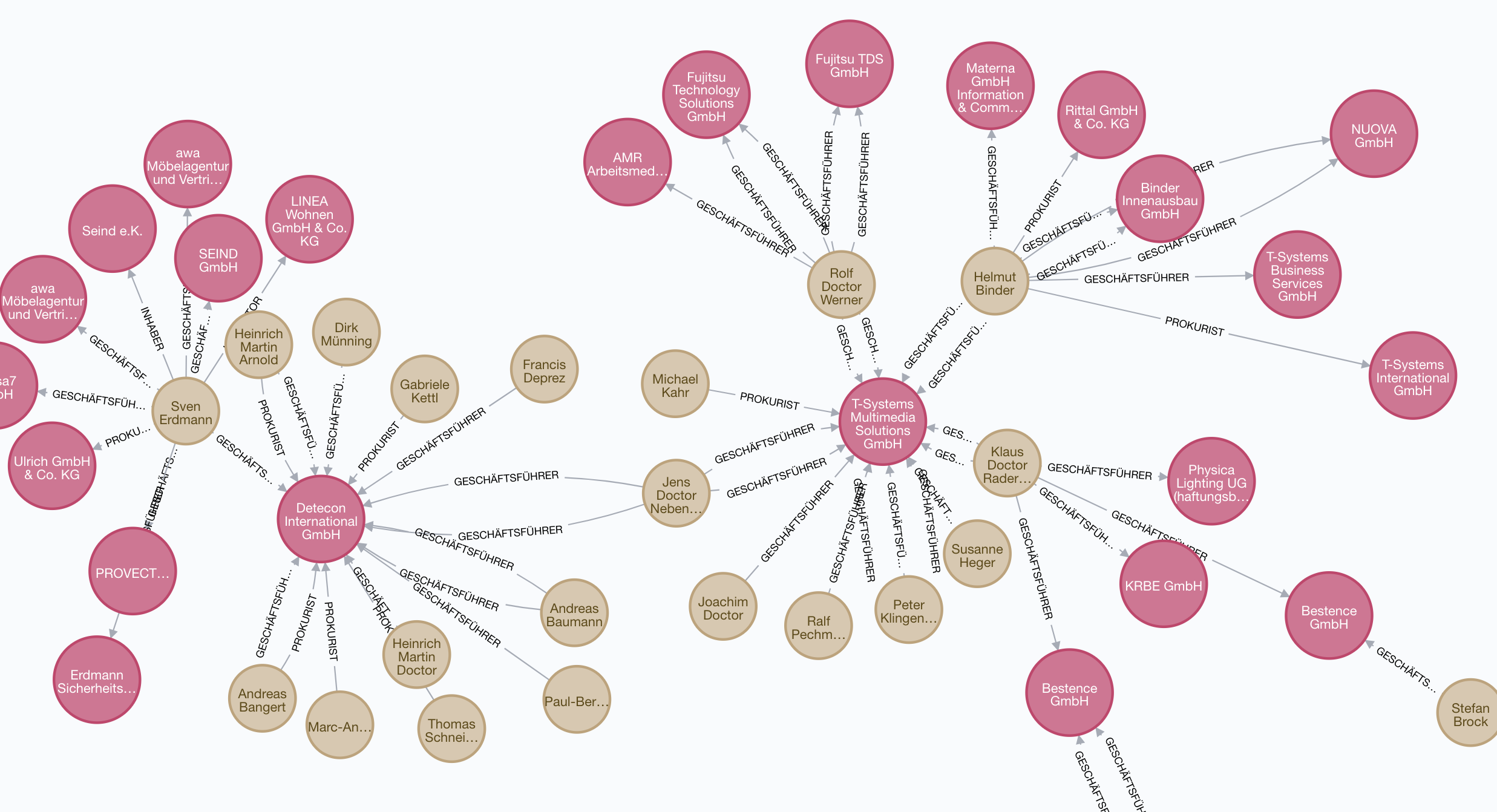
Identities
Opencorporates posted a blog post
recently detailing that the native_company_number
Dealing with identities is always a problem when working with data: As I don’t have any identifying data
for the :Officer
Loading JSONL
As I learned, apoc.load.json()apoc.load.json()apoc.periodic.iterate()
// run the second statement for each item returned by the first statement.
// Returns number of batches and total processed rows
apoc.periodic.iterate('statement returning items', 'statement per item',
{batchSize:1000,iterateList:true,parallel:false,params:{},concurrency:50,retries:0})
YIELD batches, totalCreating dynamic relationships
For the relations between officers and companies, I want to use the positionforeachapoc.create.relationship()
// create relationship with dynamic rel-type
apoc.create.relationship(fromNode,'KNOWS',{key:value,…}, toNode)All that is needed is to uppercase the position
call apoc.create.relationship(officer, toUpper(replace(o.position, ' ', '_')),
{dismissed:o.other_attributes.dismissed, startDate:date(o.start_date), endDate:date(o.end_date)},company)
yield relThe final import script is much nicer and loads all data in about 10 minutes:
call apoc.periodic.iterate("call apoc.load.json('http://localhost:8000/de_companies_ocdata.jsonl') yield value as c",
"create (company:Company) set company.id = c.company_number, company.name = c.name,
company.status = c.current_status, company.jurisdictionCode = c.jurisdiction_code,
company.address = c.registered_address, company.registerArt = c.all_attributes._registerArt,
company.registerNummer = c.all_attributes._registerNummer,
company.registerOffice = c.all_attributes.registered_office,
company.nativeCompanyNumber = c.all_attributes.native_company_number,
company.previusNames=[p IN c.previous_names | p.company_name],
company.federalState = c.all_attributes.federal_state,
company.registrar = c.all_attributes.registrar
with c, company UNWIND c.officers as o
merge (officer:Officer {name:o.name}) on create set officer.firstName = o.other_attributes.firstname,
officer.lastName = o.other_attributes.lastname, officer.registeredOffice = c.all_attributes.registered_office
with officer, o, company
call apoc.create.relationship(officer, toUpper(replace(o.position, ' ', '_')),
{dismissed:o.other_attributes.dismissed, startDate:date(o.start_date), endDate:date(o.end_date)},
company) yield rel
return count(officer)
", {})