

Neo4j’s Cypher is a powerful query language to work with connected data. If the provided functionality is not enough, then there is APOC to fill in the missing bits. I recommend to try and stay with Cypher and APOC as much as possible. Sometimes, the rules are too complex to express in Cypher and we need to use the Java API.
The Java API is available to Neo4j plugins, which implies that you package your code in a .jar and deploy it inside the /plugin/ folder of your Neo4j installation. This also means that you need to restart Neo4j to change the plugin.
The neo4j-procedure-template is a good starting point as it contains examples and maven pom file that builds a jar file ready for deployment.
Part of the Java API is the Traversal framework that allows describing the traversal (query) you want to perform and then let the framework handle the actual work.
The framework is single-threaded, simplifies the usage. Given the assumption that in a typical database usage multiple users are performing queries, the single-thread approach should still utilize the power of modern CPUs.
Note | There is a big red depreciation warning on the traversal API. While it is true that there are plans to remove the current API, there is no replacement yet and it is save to assume that the API will be available at least for the next major release. |
To explain the concepts and components involved, I will be using the following sample graph. While this graph is simple and does warrant the use of a plugin, I hope it will serve to illustrate how to use the API.
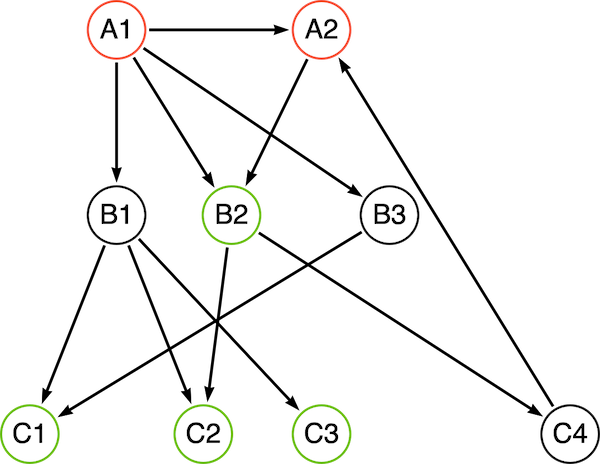
Traversal description
The traversal always starts with one or more start nodes, and we can configure how to expand from each node (which relationships to follow). For this, each traversal has one Expander/PathExpander configured, that is called at each node. The traversal than needs to know which nodes (actually the path leading to that node) should be part of the result set. The traversal can optionally also take care not to visit nodes/relationships more than ones.
Let’s assume that, starting from the red A nodes, we want to collect at least 2 green C nodes. We would first need to construct our traversal configuration (aka TraversalDescription):
TraversalDescription traverseDescription = db.beginTx().traversalDescription() (1)
.uniqueness(NODE_GLOBAL) (2)
.breadthFirst() (3)
.expandand(new AllExpander()) (4)
.evaluationluator(new GreenEvaluator(minimumGreen)) (5)we obtain a traversal description from a transaction, so we can modify it
set the uniqueness to the default value
breadth-first or depth-first, see below
set an Expander that returns relationships to follow for each node
we configure an Evaluator that determines if a path should be collected into the result and if traversal for this branch should continue.
After the configuration of the traversal, the traversal can be started by passing one or more start nodes. The returned Traverser object than has methods to access the result.
Traverser traverser = traverseDescription.traverse(startNodes);Expander/PathExpander
For each step (node) in the traversal, we get to decide how to expand, aka, which relationships to follow. For this, the TraversalDescription has exactly one Expander configured. A sample implementation could look like this:
public static class AllExpander implements PathExpander<List<String>> {
@Override
public Iterable<Relationship> expand(Path path, BranchState<List<String>> branchState) {
PathLogger.logPath(path, "exp", branchState);
// expand along all relationships
// there is a ALLExpander provided, this is here to show the interface
final ArrayList<String> newState = new ArrayList<>(branchState.getState());
newState.add((String)path.endNode().getProperty("name"));
branchState.setState(newState);
return path.endNode().getRelationships(Direction.OUTGOING);
}
@Override
public PathExpander<List<String>> reverse() {
return null;
}
}There is one function expandand() that needs to be implemented (there is also reverse() that needs to be there, but we can rust return null there). The API provides a few implementations of the PathExpander interface in PathExpanders:
allTypesAndDirections()
forType()
forTypeAndDirection()
so for simple cases (as in the example above), there is no need to implement them.
There is also the option to pass state along using the type parameter of the interface.
State
The traversal API can move state along. The BranchState is accessible from PathExpanders as well as from the PathEvaluator. Changes to the state are only visible 'downstream'. Usage of that state can greatly simplify the design of your traversal logic.
Note | The traversal API has the notion of Branch. Whenever the API follows a relationship form a node (A) to a node (B), a new branch is created. The branch for B has the branch A as a parent. State is only passed from parent to child, not the other way around. |
You can see how the state changes during the traversal in the tables below.
Order
The order determines which of the relationships returned from an Expander are traverse next. This is configured by passing an implementation of the BranchOrderingPolicy interface to the TraversalDescription via the order() call. The API comes with 2 implementations:
Depth-First
Expanding and evaluating children of a node first before the siblings of a node. In our example graph, the traversal would look like the following:
| Traversal always starts with provided starting nodes, in our case A1 and A2. Before expansion, the node is evaluated and depending on the return value of the
|
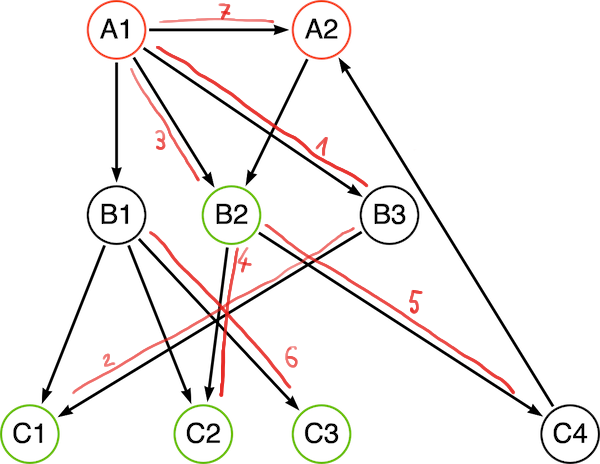
| Phase | State | Path |
|---|---|---|
evaluation | [] | (A1) |
evaluation | [] | (A2) |
expand | [] | (A1) |
evaluation | [A1] | (A1)-[RELATED]-(B3) |
expand | [A1] | (A1)-[RELATED]-(B3) |
evaluation | [A1, B3] | (A1)-[RELATED]-(B3)-[RELATED]-(C1) |
expand | [A1, B3] | (A1)-[RELATED]-(B3)-[RELATED]-(C1) |
evaluation | [A1] | (A1)-[RELATED]-(B2) |
expand | [A1] | (A1)-[RELATED]-(B2) |
evaluation | [A1, B2] | (A1)-[RELATED]-(B2)-[RELATED]-(C2) |
expand | [A1, B2] | (A1)-[RELATED]-(B2)-[RELATED]-(C2) |
evaluation | [A1, B2] | (A1)-[RELATED]-(B2)-[RELATED]-(C4) |
expand | [A1, B2] | (A1)-[RELATED]-(B2)-[RELATED]-(C4) |
evaluation | [A1] | (A1)-[RELATED]-(B1) |
expand | [A1] | (A1)-[RELATED]-(B1) |
evaluation | [A1, B1] | (A1)-[RELATED]-(B1)-[RELATED]-(C3) |
expand | [A1, B1] | (A1)-[RELATED]-(B1)-[RELATED]-(C3) |
expand | [] | (A2) |
Breath-First
Not to be confused with bread first, this will first go for the siblings of a node before following 'down' to the children:
| Phase | State | Path |
|---|---|---|
evaluation | [] | (A1) |
evaluation | [] | (A2) |
expand | [] | (A1) |
expand | [] | (A2) |
evaluation | [A1] | (A1)-[RELATED]-(B3) |
evaluation | [A1] | (A1)-[RELATED]-(B2) |
evaluation | [A1] | (A1)-[RELATED]-(B1) |
evaluation | [A2] | (A2)-[RELATED]-(C4) |
expand | [A1] | (A1)-[RELATED]-(B3) |
evaluation | [A1, B3] | (A1)-[RELATED]-(B3)-[RELATED]-(C1) |
expand | [A1] | (A1)-[RELATED]-(B2) |
evaluation | [A1, B2] | (A1)-[RELATED]-(B2)-[RELATED]-(C2) |
expand | [A1] | (A1)-[RELATED]-(B1) |
evaluation | [A1, B1] | (A1)-[RELATED]-(B1)-[RELATED]-(C3) |
expand | [A2] | (A2)-[RELATED]-(C4) |
expand | [A1, B3] | (A1)-[RELATED]-(B3)-[RELATED]-(C1) |
expand | [A1, B2] | (A1)-[RELATED]-(B2)-[RELATED]-(C2) |
expand | [A1, B1] | (A1)-[RELATED]-(B1)-[RELATED]-(C3) |
I used a list of node names as an example only. You can use the state to pass a calculated weight, costs, counters or complex data structures along.
Complete source code of the example above together with a simple test can be found in the repository in the org.faboo.example.traversal package.